9.2 Yerel Vekil (LIME)
Yerel vekil modeller, kara kutu modellerin tekil tahminlerini açıklamak için kullanılan yorumlanabilir modellerdir. Yerel, yorumlanabilir ve modelden bağımsız açıklamalar (LIME)50, yazarların elle tutulur bir yerel vekil modeli uygulaması ortaya koyduğu bir makaledir. Vekil modeller, kara kutu modellerin sonuçlarını tahmin etmek üzere eğitilirler. LIME, evrensel bir vekil model eğitmek yerine, tekil tahminleri açıklamak üzere yerel vekil modeller eğitmeye odaklanır.
LIME'ın arkasındaki fikir gayet anlaşılırdır. Önce, eğitim verisini bir yana bırakıp, elinizde sadece girdileri verip tahminleri alabileceğiniz bir kara kutu model olduğunu düşünün. Bu kara kutuyu bu şekilde istediğiniz kadar inceleyebilirsiniz. Amacınız bu modelin belli tahminleri nasıl aldığını anlamaktır. LIME, modele verinin hafifçe değiştirilmiş varyasyonlarını verdiğinizde tahminin nasıl değiştiğini test eder, bu hafifçe değiştirilmiş örneklerle ve modelin o örnekler için yaptığı tahminlerle yeni bir veri seti oluşturur. Daha sonra LIME, yeni örneklerin, tahminini açıklamak istediğimiz örneğe olan uzaklığıyla ağırlıklandırılmış yorumlanabilir modeli bu yeni veri setiyle eğitir. Buradaki yorumlanabilir model, yorumlanabilir modeller bölümündeki herhangi bir model olabilir (örneğin Lasso veya karar ağaçları). Eğitilen model, açıklamak istediğimiz kara kutu modelin tahminlerini yerel olarka iyi tahmin ediyor olmalı, fakat iyi bir evrensel tahmin olmasına gerek yok. Bu tür doğruluğa aynı zamanda yerel uygunluk da denir.
Matematiksel olarak yerel vekil modelleri, yorumlanabilirlik şartıyla da birlikte, aşağıdaki şekilde ifade edilebilir:
\[\text{açıklama}(x)=\arg\min_{g\in{}G}L(f,g,\pi_x)+\Omega(g)\]
x örneği için açıklama modeli (örneğin lineer regression); modelin karmaşıklığını \(\Omega(g)\) düşük tutarken (örneğin az sayıda öznitelik kullanarak), açıklamanın asıl modelin (örneğin xgboost) tahminine ne kadar yakın olduğunu ölçen L hatasını (örneğin ortalama hata karesi) minimize eden modeldir. G, olası açıklamaların kümesidir (örneğin olası tüm lineer regression modelleri). Yakınlık ölçüsü \(\pi_x\), x örneği etrafındaki açıklama için kullanacağımız komşuluk sınırının ne kadar büyük olduğunu belirler. Pratikte LIME sadece hata terimini optimize eder, model karmaşıklığını kullanıcının belirlemesi gerekir (lineer regression'ın kullanabileceği öznitelik sayısına sınır koymak).
Yerel vekil modellerini eğitmenin tarifi:
- Kara kutu modelin onun için yaptığı tahmini açıklamak istediğiniz örneği seçin.
- Veri setini hafifçe değiştirin ve kara kutu modelin bu yeni veriler için yaptığı tahminleri hesaplatın.
- Yeni örnekleri, orijinal örneğe olan uzaklığına göre ağırlıklandırın.
- Ağırlıklandırılmış, yorumlanabilir modeli örneğin varyasyonlarını içeren veri setiyle eğitin.
- Yerel modeli yorumlayarak tahmini açıklayın.
LIME'ın R ve Python'daki mevcut implementation'larında, örnek olarak, lineer regression modelini yorumlanabilir vekil model olarak seçebilirsiniz. Öncesinde K değerini, yani yorumlanabilir modelde olmasını istediğiniz öznitelik sayısını seçmelisiniz. Düşük K değeri daha iyi yorumlanabilen modeller demek iken, yüksek K değerleri potansiyel olarak yüksek uygunluklu modeller üretir. K tane öznitelik içeren modeller eğitmek için birkaç metot mevcuttur. İyi tercihlerden biri Lasso'dur. Yüksek \(\lambda\) değeri herhangi bir özniteliği olmayan modeller ortaya çıkarabilir. \(\lambda\) değerini düşürerek eğittiğimiz Lasso modeli, özniteliklere sıfır dışında ağırlıklar vermeye başlar. K tane özniteliğe ulaştığınızda istediğiniz sayıda özniteliğe sahipsiniz demektir. İleri ya da geri yönlü öznitelik seçimi diğer yöntemlerdir: Ya tüm öznitelikleri içeren tam modelle başlayıp öznitelik çıkartarak, ya da sadece intercept değerine sahip modelle başlayıp öznitelik ekleyerek performansa en iyi katkıyı hangi özniteliğin yaptığına göre karar verip K tane özniteliğe ulaşana kadar devam edebilirsiniz.
Peki verinin varyasyonlarını nasıl elde edilir? Bu verinin türüne bağlıdır; veri metin, görsel veya tablo verisi olabilir. Metin ve görseller için çözüm, kelimeleri veya süper-pikselleri açıp kapatmaktır. Tablo verisinde ise LIME, her bir özniteliği, özniteliğin ortalama ve standart sapma değerlerine sahip normal dağılımla hafifçe değiştirerek yeni örnekler oluşturur.
9.2.1 Tablo verisi için LIME
Tablo verisinde her satır bir örneği ve her sütun bir özniteliği temsil eder. LIME örnekleri açıklamak istediğimiz örneğin çevresinden değil, eğitim verisinin kütle merkezinden alınır, bu durumu biraz problematiktir ama bazı örneklerin tahminleri için elde edilen sonucun ilgilendiğimiz örneğin tahmini için bulunan sonuçtan farklı olması olasılığını arttırdığından bu sayede LIME garanti olarak bir açıklama öğrenebilir.
Örneklemenin ve modeli yerel bir bölgede eğitmenin nasıl çalıştığını görsellerle daha iyi anlayabiliriz:
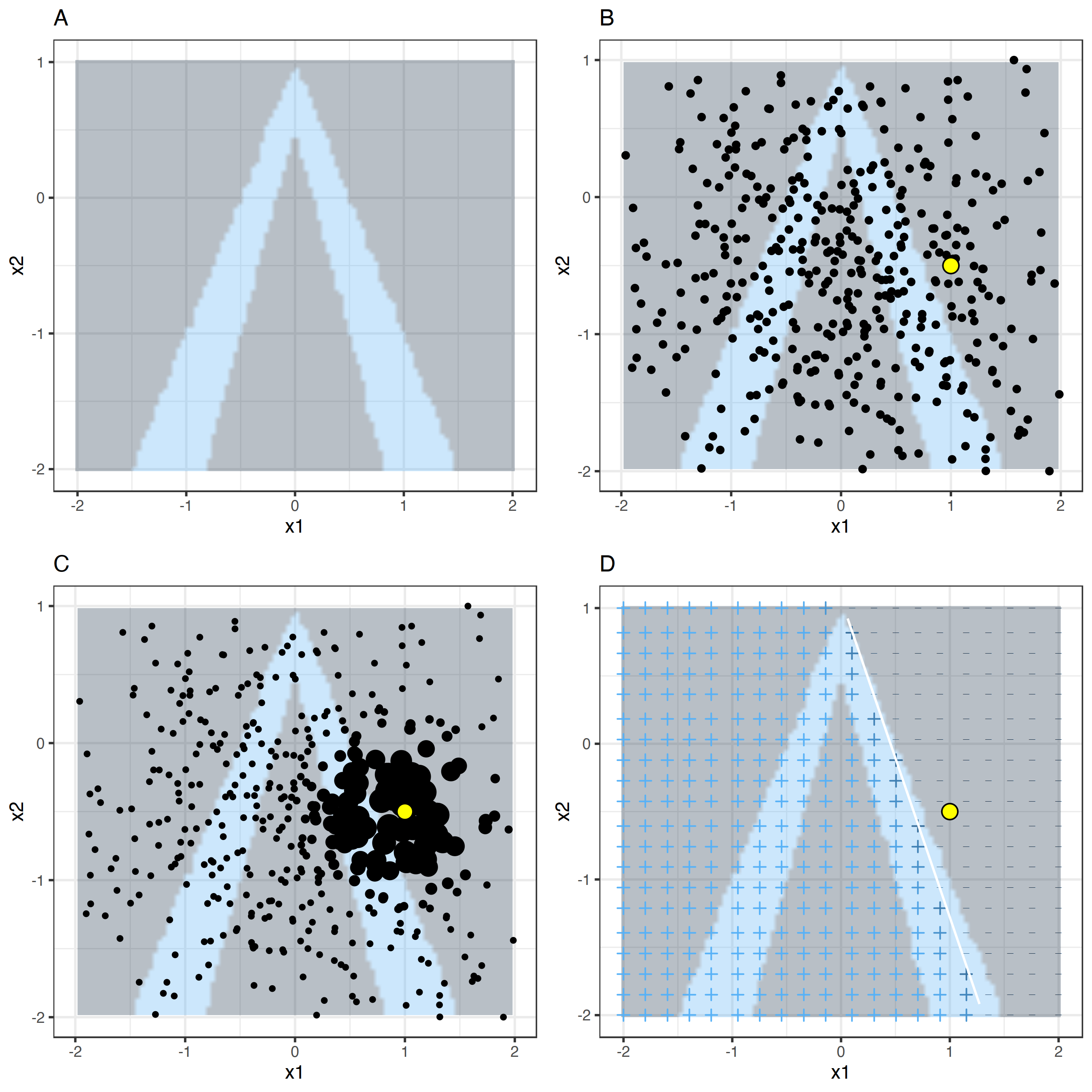
ŞEKİL 9.5: Tablo verisi için LIME algoritması. A) Rastgele orman algoritmasının x1 ve x2 öznitelikleriyle yaptığı tahminler. Tahmin edilen sınıflar: 1 (karanlık) ya da 0 (aydınlık). B) İlgilendiğimiz örnek (büyük nokta) ve normal dağılımdan örneklenen veriler (küçük noktalar). C) İlgilendiğimiz örneğe daha yakın örneklere daha büyük ağırlıklar verilir. D) + ve - işaretleri yerelde, ağırlıklandırılmış örneklerle eğitilen modelin sınıflandırmasını gösterir. Beyaz çizgi karar sınırını belirtir (P(class=1) = 0.5).
Her zaman olduğu gibi, şeytan ayrıntıda gizlidir. Bir noktanın etrafında anlamlı bir komşuluk tanımlamak zordur. LIME bu komşuluğu belirlemek için eksponansiyel yumuşatma kernel'ı kullanır. Yumuşatma kernel'ı iki veri örneğini alıp bir uzaklık ölçüsü veren bir fonksiyondur. Kernel genişliği komşuluğun büyüklüğünü belirler: Küçük kernel genişliği, bir örneğin yerel modeli etkileyebilmesi için çok yakın olması gerektiği; büyük kernel genişliği, uzaktaki örneklerin de modeli etkileyeceği anlamına gelir. LIME'ın Python koduna(file lime/lime_tabular.py) bir göz atarsanız eksponansiyel yumuşatma kernel'ı kullandığını ve kernel genişliğinin eğitim verisindeki sütun sayısının karekökünün 0.75 katı olduğunu göreceksiniz. Masum bir kod gibi görünse de, odadaki fil şudur ki en iyi kernel fonksiyonunu ya da genişliğini bulmak bir problemdir. 0.75 de nereden çıktı? Belli senaryolarda kernel genişliğini değiştirerek açıklamanızı tam tersine çevirebilirsiniz:
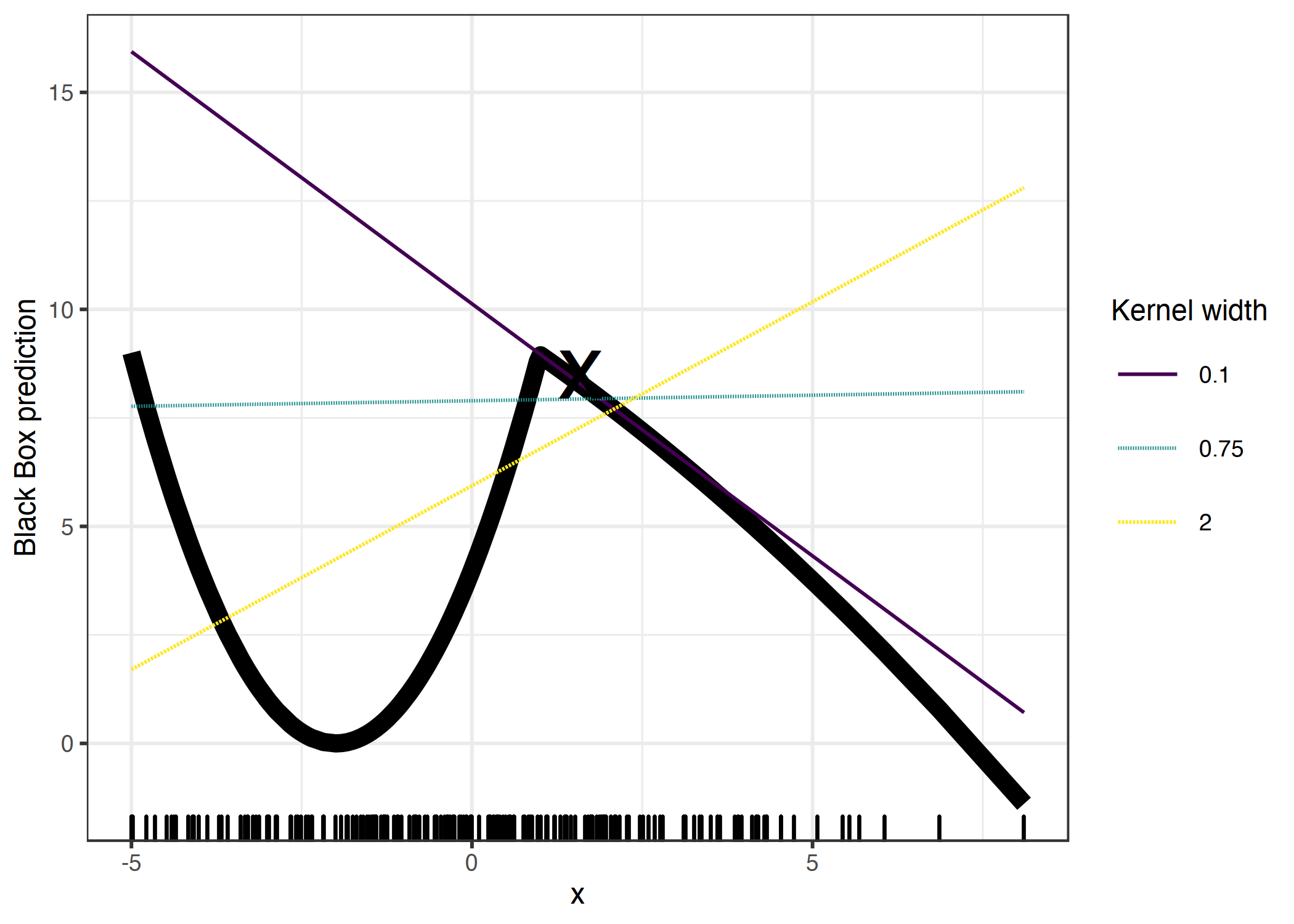
ŞEKİL 9.6: x = 1.6 örneğinin açıklaması. Tek özniteliği olan kara kutu modelin tahminleri kalın çizgiyle, ve verinin dağılımı aşağıdaki çubuklarla gösterilmiştir. Üç farklı kernel genişliğiyle üç farklı yerel vekil model oluşturuldu. Elde edilen lineer regression modeli kernel genişliğine bağlıdır: x = 1.6 örneği için öznitelik nasıl bir etki (negatif, pozitif veya nötr) yapar?
Yukarıdaki durumda sadece tek bir öznitelik için farklı açıklamalar var, öznitelik uzayının boyutu arttıkça durum daha da kötüleşecektir. Ayrıca uzaklık ölçüsünün tüm özniteliklere aynı şekilde davranıp davranmaması gerektiği de açık değildir. x1 özniteliğindeki bir birim uzaklık x2 özniteliğindekine denk midir? Uzaklık ölçüleri oldukça keyfidir ve farklı eksenlerdeki (özniteliklerdeki) uzaklıkların karşılaştırılması mümkün olmayabilir.
9.2.1.1 Örnek
Gerçek bir örnekle devam edelim. Bisiklet kiralama verisetine geri dönecek ve onu bir sınıflandırma problemine dönüştüreceğiz: Bisiklet kiralamasının zamanla daha popüler olduğu trendini göz önüne aldıktan sonra, şimdi de belli bir günde kiralanan bisiklet sayısının trend çizgisinden aşağıda mı yukarıda mı olduğunu araştıracağız. "Yukarı"yı ortalama bisiklet sayısının yukarısında olarak da yorumlayabilirsiniz, burada sadece trende uyduruldu.
Önce sınıflandırma için 100 ağaçlı bir rastgele orman eğiteceğiz. Hava ve takvim bilgisine göre, hangi günde kiralanan bisiklet sayısı ortalamanın üstünde olacak?
Açıklamalar 2 öznitelikle oluşturuluyor. Tahmin edilen sınıfı farklı olan iki veri örneği için ayrık yerel lineer modellerin sonucu:
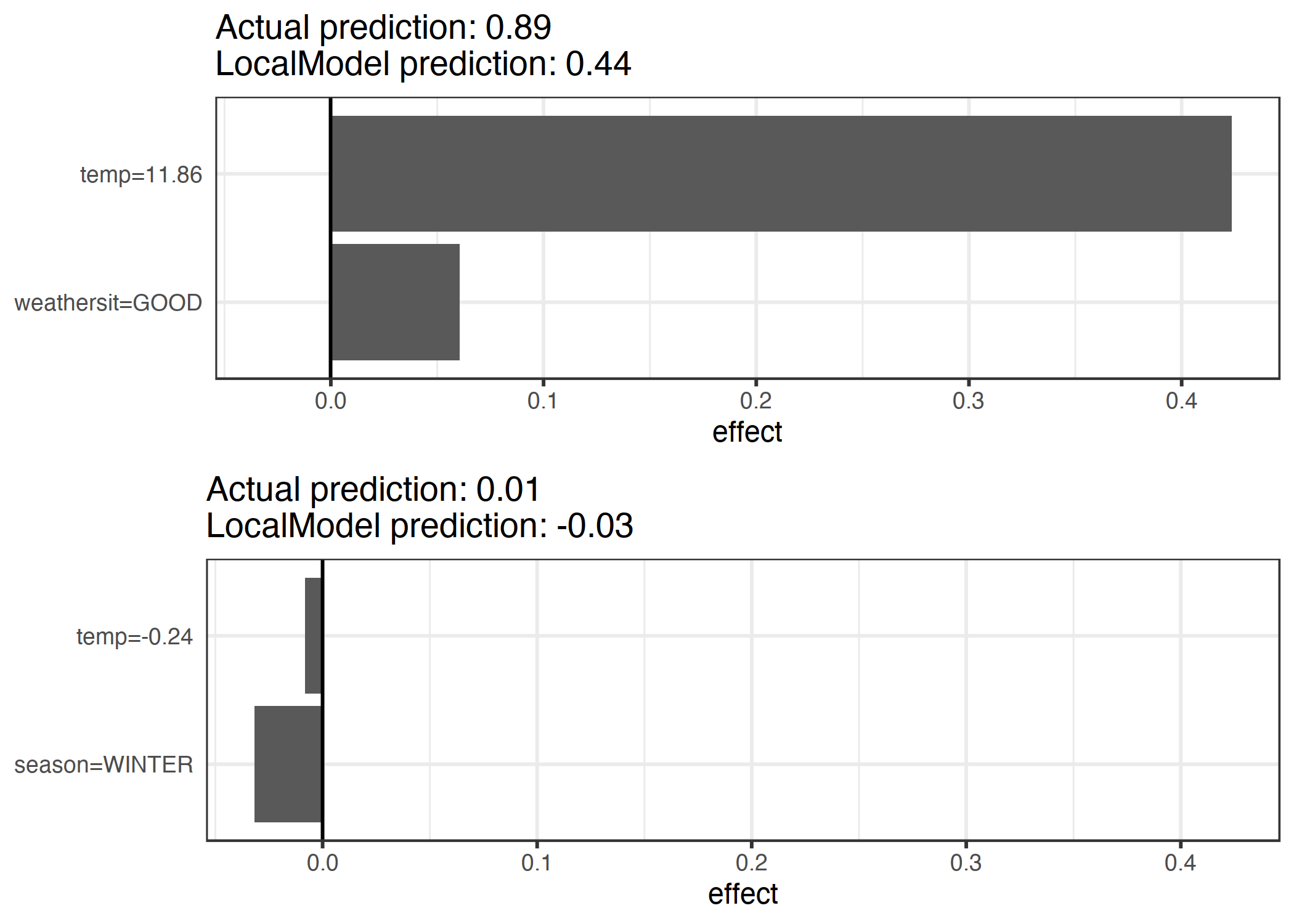
ŞEKİL 9.7: Bisiklet kiralama verisetinden iki örnek için LIME açıklamaları. Yüksek sıcaklık ve iyi hava tahmine pozitif etki ediyor. x ekseni öznitelik etkisini gösteriyor: Ağırlık çarpı özniteliğin değeri.
Şekilden daha iyi anlaşılacağı üzere, kategorik öznitelikleri yorumlamak sayısal olanları yorumlamaktan daha kolay. Buna dair bir çözüm sayısal özniteliği aralıklara bölmektir.
9.2.2 Metin Verisi için LIME
LIME'ın metin verisinde kullanımı tablo verisinden farklıdır. Veri varyasyonları farklı bir şekilde oluşturulur: Orijinal metindeki kelimeleri rastgele silerek yeni metinler oluşturulur. Veriler her kelimenin ikili öznitelik değerleriyle gösterilir, yani özniteliğin aldığı değer 1 ise kelime o metinde yer alıyor, 0 ise yer almıyor demektir.
9.2.2.1 Örnek
Bu örnekte YouTube yorumlarını spam veya normal olarak sınıflandıracağız.
Kara kutu model, dökümantasyon kelime matrisiyle eğitilmiş derin bir karar ağacıdır. Her yorum bir dökümantasyona (bir satıra) ve her sütun o kelimenin yorumda kaç kez bulunduğuna denk gelir. Kısa karar ağaçlarını anlaması kolaydır fakat bizim durumumuzda ağaç oldukça derin. Ayrıca bu karar ağacı yerine kelime embedding'leri üzerinde eğitilmiş bir RNN veya SVM de kullanılabilir. Verisetinden iki yorumu ve sınıflarını inceleyelim:
| CONTENT | CLASS | |
|---|---|---|
| 267 | PSY is a good guy | 0 |
| 173 | For Christmas Song visit my channel! ;) | 1 |
Sonraki adım yerel modelde kullanacağımız, orijinal verinin varyasyonlarını oluşturmak. Örneğin yorumlardan birinin varyasyonları şu şekilde:
| For | Christmas | Song | visit | my | channel! | ;) | prob | weight |
|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 1 | 1 | 0 | 0 | 1 | 0.17 | 0.57 |
| 0 | 1 | 1 | 1 | 1 | 0 | 1 | 0.17 | 0.71 |
| 1 | 0 | 0 | 1 | 1 | 1 | 1 | 0.99 | 0.71 |
| 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0.99 | 0.86 |
| 0 | 1 | 1 | 1 | 0 | 0 | 1 | 0.17 | 0.57 |
Her sütun cümledeki bir kelimeye denk gelir. Her satır farklı bir varyasyondur; 1, o kelimenin o varyasyonda bulunduğu, 0 ise kelimenin
kaldırıldığı anlamına gelir. Varyasyonlardan biri "Christmas Song visit my ;)" şeklindedir. "prob" sütunu cümle için modelin
tahmin ettiği spam olma olasılığını belirtir. "weight" satırı varyasyonun orijinal cümleye olan uzaklığını belirtir ve 1 - kaldırılan kelime sayısı
şeklinde hesaplanır; örneğin 7 kelimeden 1'i kaldırılmışsa, uzaklık 1 - 1/7 = 0.86 olur.
Aşağıda biri spam diğeri normal iki cümle LIME algoritmasının hesapladığı yerel ağırlıklarla birlikte verilmiştir:
| case | label_prob | feature | feature_weight |
|---|---|---|---|
| 1 | 0.1701170 | good | 0.000000 |
| 1 | 0.1701170 | a | 0.000000 |
| 1 | 0.1701170 | is | 0.000000 |
| 2 | 0.9939024 | channel! | 6.180747 |
| 2 | 0.9939024 | For | 0.000000 |
| 2 | 0.9939024 | ;) | 0.000000 |
"channel" kelimesi yüksek spam olasılığına işarettir. Spam olmayan yorumdaki hiçbir kelime için sıfırdan farklı bir ağırlık hesaplanmamış, çünkü hangi kelime kaldırılırsa kaldırılsın tahmin edilen sınıf aynı kalıyor.
9.2.3 Görseller için LIME
Bu bölüm Verena Haunschmid tarafından yazıldı.
Görseller için LIME, metin ve tablo verisinde olduğundan farklı çalışıyor. Birden çok piksel bir sınıfın tahmin edilmesine yardımcı olduğundan pikselleri tek tek değiştirmenin bir anlamı yoktur, pikselleri rastgele değiştirmek tahmin edilen olasılığı pek değiştirmeyecektir. Bu yüzden görsel verisinin varyasyonları, görselleri "süper-piksellere" bölerek ve onları kapatıp açarak elde edilir. Süper-pikseller benzer renklere sahip birbirine bağlanmış piksellerdir ve her pikseli kullanıcının belirlediği bir renkle (örneğin gri ile) değiştirerek kapatıp açılabilir. Kullanıcı aynı zamanda her permütasyonda bir süper-pikselin kapanma olasılığını belirleyebilir.
9.2.3.1 Örnek
Bu örnekte Inception V3 sinir ağı tarafından yapılan bir sınıflandırmayı inceleyeceğiz. Görselde, yaptığım ekmekler bir kasenin içinde duruyor. Bir görsel için tahmini olasılığına göre sıralanmış birden çok sınıf olabileceğinden, en olası sınıfı seçip onu açıklayacağız. Bu görsel için en yüksek olasılık %77 ile "Bagel" sınıfı, onu 4% olasılıkla "Strawberry" takip ediyor. Aşağıdaki görsellerde her iki sınıf için oluşturulan LIME açıklamaları yer alıyor. Açıklamalar doğrudan görseller üzerinde görselleştirilebilir. Yeşil renk, o bölgenin o sınıfın tahmin edilmesi olasılığını arttırdığını, kırmızı ise azalttığını belirtiyor.

ŞEKİL 9.8: Sol: Bir kase ekmek görseli. Orta ve sağ: Google'ın Inception V3 sinir ağına göre bu görsel için en yüksek olasılıklı iki sınıf için (simit, çilek) LIME açıklamaları
"Bagel" sınıfında yapılan tahmin yanlış olsa da (ekmeklerin ortalarında bir delik yok), tahmin ve açıklama gayet mantıklı.
9.2.4 Avantajlar
Tek bir yerel ve yorumlanabilir modeli, tahminlerini açıklamak istediğiniz herhangi bir kara kutu model için kullanabilirsiniz. Açıklamaları inceleyen kullanıcıların en iyi anladığı modelin karar ağaçları olduğunu varsayalım. Yerel vekil modeller kullandığınızdan, tahminler için karar ağaçlarını kullanmasanız da açıklamalar için karar ağaçlarını kullanabilirsiniz. Örneğin, bir SVM ile başlarsınız, xgboost modeli daha iyi çalışıyorsa SVM modelini değiştirirsiniz ama yine de açıklamalar için karar ağaçları kullanmaya devam edebilirsiniz.
Yerel vekil modeller, yorumlanabilir modelleri eğitmenin ve yorumlamanın tecrübesinden ve araştırma geçmişinden faydalanır.
Lasso ya da kısa ağaçlar kullandığınızda, elde ettiğiniz açıklamalar kısa (yani seçici) ve yüksek olasılıkla zıtlıklar üzerine olur. Bu özelliklerinden ötürü bu açıklamalar insan dostu açıklamalardır, ve bu yüzden LIME, açıklamanın alıcısının meslek dışından veya az zamanı olan biri olduğu durumlarda daha çok tercih edilir. Bütünsel açıklamalar üretemediğinden LIME metodunu yasal bir durumda tahminleri açıklamanız gereken senaryolarda kullanılabilir görmüyorum. Aynı zamanda makine öğrenmesi modellerini debug ederken tüm nedenleri görebilmek birkaçını görmekten çok daha kullanışlıdır.
LIME, hem tablo, hem metin, hem de görsel verisi için çalışabilen nadir metotlardandır.
Uygunluk ölçüsü (yorumlanabilir modelin kara kutu modeli ne kadar iyi taklit edebildiği), yorumlanabilir modelin ilgilendiğimiz veri örneği etrafında kara kutu modeli ne kadar iyi açıklayabildiğine dair iyi bir bilgi verir.
LIME'ın Python (lime library) ve R (lime package and iml package) implementation'ları mevcuttur ve kullanımları gayet basittir.
Yerel modellerle yapılan açıklamalar, asıl modelin kullanmadığı (yorumlanabilir) öznitelikler kullanabilir. Tabii ki bu yorumlanabilir özniteliklerin eldeki verilerden türetilmesi gerekir. Bir metin sınıflandırıcısı kelime embedding'lerini öznitelikler olarak alırken yapılan açıklamalar cümlede olan veya olmayan kelimeler üzerine yapılabilir. Bir regression modeli yorumlanabilir olmayan, özniteliklerin dönüştürülmüş hallerine dayanırken açıklamalar orijinal özniteliklere dayanabilir. Örneğin, regression modeli bir ankete verilen cevapların PCA (principal component analysis) öznitelikleriyle eğitilirken LIME orijinal anket cevaplarıyla eğitilebilir. Özellikle kara kutu modelin öznitelikleri yorumlanabilir olmadığında, LIME için yorumlanabilir öznitelikler kullanmak avantaj sağlayabilir.
9.2.5 Dezavantajlar
Tablo verisi için LIME metodunda, komşuluğun ne olduğunun tanımı çözülememiş büyük bir problemdir. Benim görüşüm bu durumun LIME'ın en büyük problemi olduğu ve bu yüzden metodu kullanırken çok dikkatli olmanız gerektiği yönünde. Her farklı senaryo için farklı kernel ayarları denemeniz ve açıklamaları kendiniz test etmeniz gerekmektedir, ve maalesef uygun kernel genişliğini bulmak için verebileceğim en iyi tavsiye budur.
Örnekleme işlemi geliştirilmeye açıktır. Veri örnekleri, öznitelikler arasındaki korelasyon görmezden gelinerek Gaussian bir dağılımdan alınır. Bu, yerel yorumlanabilir modelleri eğitirken gerçekçi olmayan veriler kullanmanıza sebep olabilir.
Açıklama modelinin karmaşıklığı önceden belirlenmelidir. Bu aslında küçük bir problemdir, çünkü kullanıcının her zaman uygunluk ve ayrıksılık arasında alış veriş yapması gereklidir.
Bir diğer problem ise açıklamaların istikrarsızlığıdır. Bir makalede 51 yazarlar, iki çok yakın veri örneği için yapılan açıklamaların oluşturulan ayarlarda çok farklı olduğunu gösterdiler. Benim de gözlemlediğim üzere, eğer örnekleme işlemini tekrar ederseniz açıklamalar değişkenlik gösterebilir. İstikrarsızlık açıklamlara güvenmenin zor olduğu ve çok titiz olmanız gerektiği anlamına gelir.
LIME açıklamaları veri bilimciler tarafından bias'leri saklamak üzere 52 manipüle edilebilir. Manipülasyon ihtimali LIME'ın ürettiği açıklamalara güvenmeyi zorlaştırır.
Sonuç: Yerel vekil modeller, ve onların bir örneği LIME, umut vaad eden metotlardır; fakat hala geliştirme sürecinde olduğundan güvenle kullanılmadan önce daha birçok problemin çözülmesi gereklidir.
Ribeiro, Marco Tulio, Sameer Singh, and Carlos Guestrin. “Why should I trust you?: Explaining the predictions of any classifier.” Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. ACM (2016).↩︎
Alvarez-Melis, David, and Tommi S. Jaakkola. “On the robustness of interpretability methods.” arXiv preprint arXiv:1806.08049 (2018).↩︎
Slack, Dylan, Sophie Hilgard, Emily Jia, Sameer Singh, and Himabindu Lakkaraju. “Fooling lime and shap: Adversarial attacks on post hoc explanation methods.” In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, pp. 180-186 (2020).↩︎