2.3 Terminoloji
Belirsizliğe dayalı kafa karışıklığından kurtulmak için önce kitapta kullanılan terimleri tanımlayalım:
Bir algoritma makinenin hedefe ulaşmak için takip ettiği kurallar bütünüdür. Girdileri, çıktıları ve girdilerden çıktılara ulaşmayı sağlayacak adımları tanımlayan bir tarif olarak düşünülebilir. Yemek tarifleri, malzemelerin girdiler, yemeğin çıktı ve yemeğin hazırlanışının algoritmanın adımları olduğu algoritmalardır.
Makine öğrenmesi bilgisayarların veriye dayalı tahminler yapmasını ve onları geliştirmesini sağlayan metotlardır (kanser teşhisi, haftalık satış tahmini ve kredi puanı hesaplama gibi). Makine öğrenmesi tüm talimatların açıkça yazıldığı normal programlamadan, veriyle çalışan dolaylı programlamaya doğru bir paradigma değişimidir.
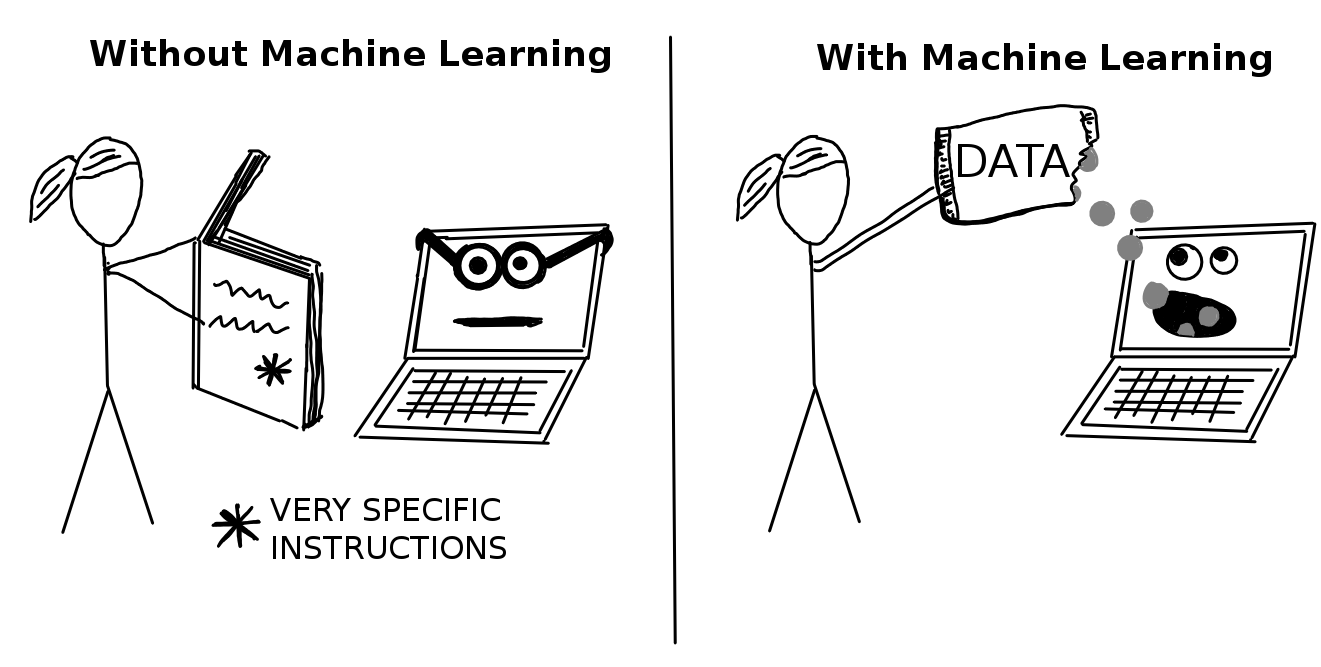
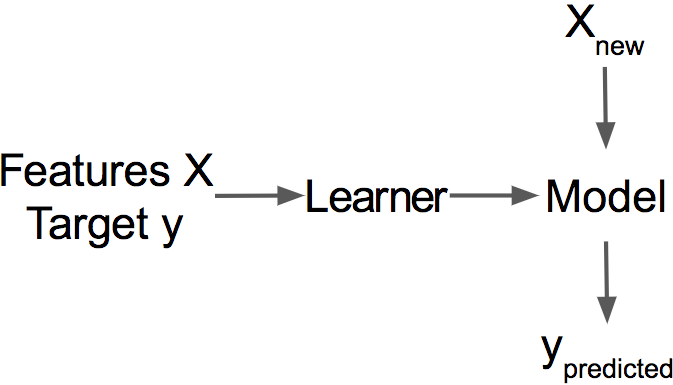
Öğreniciler veya makine öğrenmesi algoritmaları veriden modeli öğrenen programlardır. "İndükleyici" (Inducer) de denir (örneğin "tree inducer").
Makine öğrenmesi modeli girdileri tahminlerle eşleyen öğrenilmiş bir programdır. Lineer bir model veya bir sinir ağı için bir dizi ağırlık olabilir. Pek spesifik olmayan "model" kelimesi için bir diğer isim "tahmin edici" veya -probleme bağlı olarak- "sınıflandırıcı" veya "regression modeli"dir. Formüllerde, eğitilmiş makine öğrenmesi modeli \(\hat{f}\) veya \(\hat{f}(x)\) ile gösterilir.
Kara kutu modeller içindeki mekanizmaları gizli tutan sistemlerdir. Makine öğrenmesinde "kara kutu", parametrelerine bakıp anlaşılamayacak modellere denir (örneğin bir sinir ağı). Kara kutunun zıttı sistemlere bazen beyaz kutu denir, bu kitapta ise bu tür modeller yorumlanabilir model olarak anılıyor.Modelden bağımsız metotlar modellere öyle olmasalar da kara kutularmış gibi davranır.

Yorumlanabilir makine öğrenmesi terimi, makine öğrenmesi sistemlerinin davranışlarını ve tahminlerini insanlara anlaşılabilir kılan metotlardan bahsederken kullanılır.
Veriseti makinenin öğrenirken kullandığı tablodur. Özellikleri ve tahmin edeceği hedefi içerir. Bir modeli eğitmek için kullanıldığında, verisetine "eğitim verisi" (training data) denir.
Örnek, verisetindeki satırlara denir. Aynı anlama sahip diğer terimler ise şu şekildedir: veri tanesi, gözlem. Bir örnek nitelik değerlerinden (\(x^{(i)}\)) ve, eğer biliniyorsa, hedeften (\(y_i\)) oluşur.
Özellikler tahmin veya sınıflandırma için kullanılan girdilerdir. Verisetindeki sütunlara denir. Kitap boyunca özelliklerin yorumlanabildiği varsayılmıştır, yani ne anlama geldiklerini anlamak kolaydır (günlük sıcaklık veya bir insanın boyu gibi). Özelliklerin yorumlanabilir olması büyük bir varsayımdır, ama özellikleri anlamak zorsa modelin ne yaptığını anlamak çok daha zor olacaktır. Tüm özellikleri içeren matrise X, sadece bir gözlemin özelliklerini içeren vektöre ise \(x^{(i)}\) denir. Bir özelliğin tüm gözlemler için değerlerini içeren vektöre \(x_j\) ve i. gözlemin j. özelliğine \(x^{(i)}_j\) denir.
Hedef, makinenin tahmin etmek üzere öğrendiği bilgiye denir. Matematik formüllerinde bir gözlem için hedef genelde y veya \(y_i\) ile gösterilir.
Bir makine öğrenmesi görevi, veriseti, nitelikler ve hedefin birleşimidir. Hedefin türüne göre bu görev sınıflandırma, regression, sağkalım analizi, kümeleme veya aykırı değer tespiti olabilir.
Tahmin, makine öğrenmesi modelinin özelliklere dayanarak tahmin ettiği hedeftir. Bu kitapta tahmin \(\hat{f}(x^{(i)})\) veya \(\hat{y}\) ile gösteriliyor.
“Definition of Algorithm.” https://www.merriam-webster.com/dictionary/algorithm. (2017).↩︎